گروه فنی آماری آمار گستر
این وبلاگ در زمینه پروژه ها و پژوهش های آماری فعالیت داردگروه فنی آماری آمار گستر
این وبلاگ در زمینه پروژه ها و پژوهش های آماری فعالیت داردآمار پارامتری و آمار ناپارامتری
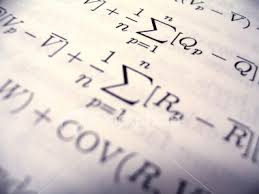
آنهایی که با آمار آشنا هستند، می دانند که معمولا با معلوم بودن نوع توزیع احتمال یک متغیر تصادفی درباره یک یا چند پارامتر مجهول، بر اساس یک نمونه تصادفی، استنباط آماری انجام می گیرد...
مثلا فرض می کنیم که وزن یک نوزاد متغیر تصادفی نرمال باشد و بخواهیم میانه این متغیر را، یعنی پارامتری که وزن پنجاه درصد از نوزادان کمتر از آن هستند، برآورد می کنیم. چون در توزیع نرمال میانگین و میانه برابرند، در نتیجه معدل نمونه، هم برآورد میانگین و هم برآورد میانه می باشد. در اینجا برآوردیابی با دانستن نوع توزیع اجرا می شود. افزون بر این با توجه به نرمال بودن توزیع، معدل نمونه بهترین برآورد برای پارامتر میانه نیست. از این رو این شاخه از آمار را «آمار وابسته به توزیع» یا در اصطلاح «آمار پارامتری» می گویند. حال فرض کنید که توزیع احتمال وزن نوزاد مجهول باشد و بخواهیم میانه را برآورد کنیم. نخست نمونه عددی وارد شده را به صورت یک رشته غیر نزولی، کوچک به بزرگ مرتب می کنیم، در صورتی که اندازه نمونه فرد باشد عدد میان این رشته، و در صورتی که اندازه نمونه زوج باشد، نصف مجموع در عدد میان این رشته را به عنوان برآورد میانه برمی گزینیم. در اینجا برآورد یابی ضمن مجهول بودن نوع توزیع احتمال وزن کودک انجام می گیرد. از این رو این شاخه از آمار را «آمار توزیع آزاد» یا در اصطلاح آمار «آمار ناپارامتری» می نامند.


























